
My own AI Agents@Home
Intro
Now that you have your own LLM at home, you may want to create your own agents. In this post, I will show you how to create your own agents using the LLM you have installed on your computer.
But first, let’s see what an agent is. Did you ever imaged to have one or more personal, intelligent and automous entities that can help with what your imagination can think of? This is what an agent is.
Pyautogen
Pyautogen is a neat opensource project that allow us to run agents on our own computer. From the official documentation:
AutoGen is a framework that enables development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
Isn’t that cool?
In my last post I showed you how to run your own model/s on your computer. Let’s use them to accomplish some tasks. You can see here the common agents’ workflow:
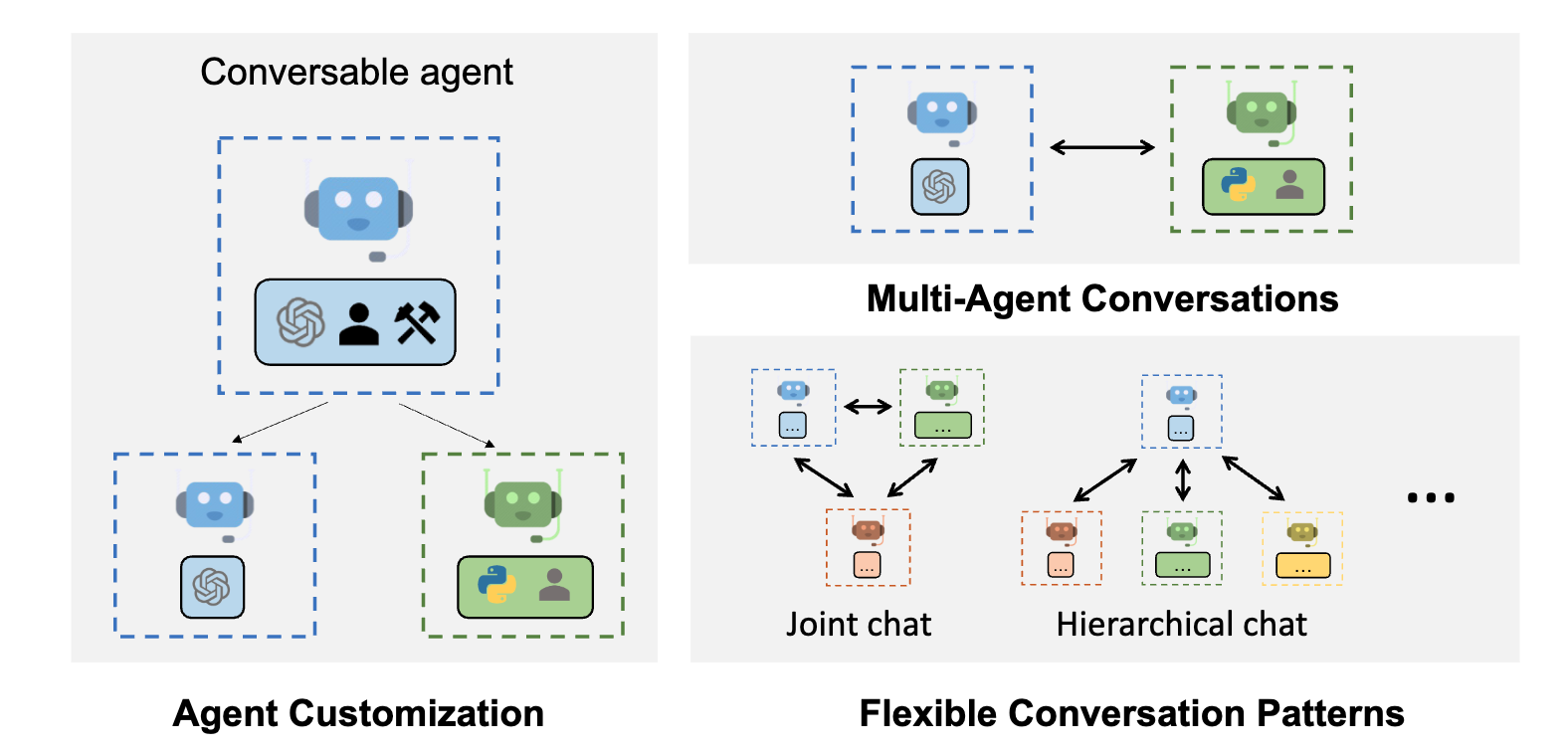
Pyautogen requires an openAI RestApi endpoint to work. It works therefore with OpenAI Agents but also with Ollama that in the latest version privides a compatible OpenAI RestApi endpoint.
Requirements
- Ollama and the models you want to use. See here how to install Ollama.
- AutoGen requires Python version >= 3.8, < 3.13.
- pyAutogen library
How to use my agents
Installation
Create a simple Python Virtual Environment and install the required packages:
python3 -mvenv .venv_autogen # Create a virtual environment
source -venv_autogen/bin/activate # Activate the virtual environment
pip install pyautogen # This install all the required packages
...
Click to expand!
Collecting pyautogen
Downloading pyautogen-0.2.26-py3-none-any.whl (264 kB)
|████████████████████████████████| 264 kB 11.1 MB/s
Collecting numpy<2,>=1.17.0
Downloading numpy-1.24.4-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (17.3 MB)
|████████████████████████████████| 17.3 MB 28.9 MB/s
Collecting pydantic!=2.6.0,<3,>=1.10
Downloading pydantic-2.7.1-py3-none-any.whl (409 kB)
|████████████████████████████████| 409 kB 147.8 MB/s
...
...
...
Collecting httpcore==1.*
Downloading httpcore-1.0.5-py3-none-any.whl (77 kB)
|████████████████████████████████| 77 kB 24.8 MB/s
Collecting exceptiongroup>=1.0.2; python_version < "3.11"
Downloading exceptiongroup-1.2.1-py3-none-any.whl (16 kB)
Collecting h11<0.15,>=0.13
Using cached h11-0.14.0-py3-none-any.whl (58 kB)
Installing collected packages: numpy, typing-extensions, pydantic-core, annotated-types, pydantic, regex, idna, certifi, charset-normalizer, urllib3, requests, tiktoken, packaging, docker, tqdm, sniffio, exceptiongroup, anyio, h11, httpcore, httpx, distro, openai, python-dotenv, termcolor, flaml, diskcache, pyautogen
Successfully installed annotated-types-0.6.0 anyio-4.3.0 certifi-2024.2.2 charset-normalizer-3.3.2 diskcache-5.6.3 distro-1.9.0 docker-7.0.0 exceptiongroup-1.2.1 flaml-2.1.2 h11-0.14.0 httpcore-1.0.5 httpx-0.27.0 idna-3.7 numpy-1.24.4 openai-1.20.0 packaging-24.0 pyautogen-0.2.26 pydantic-2.7.1 pydantic-core-2.18.2 python-dotenv-1.0.1 regex-2024.4.16 requests-2.31.0 sniffio-1.3.1 termcolor-2.4.0 tiktoken-0.6.0 tqdm-4.66.2 typing-extensions-4.11.0 urllib3-2.2.1
Run the agents
First example
In this example I’ll run 1 LLM with human interaction.
You do not need to start the model in Ollama but you have to pre-pull the model. Ollama will load and run the model for you. In this example the human is in the loop and can provide feedback to the assistant to better shape the answer. You can see the code of the fist example here example1.py
cd code/pyautogen
source .venv_autogen/bin/activate
python example1.py
user_proxy (to assistant):
What is the name of the model you are based on?
--------------------------------------------------------------------------------
assistant (to user_proxy):
I'm an AI text-based assistant and don't have a specific model name. I generate responses based on text input using a combination of natural language processing and machine learning techniques. I don't execute code or interact with the physical world directly. If you have a task for me, please specify it clearly so I can help you solve it to the best of my ability.
Here's some Python code if you want to know your current system's OS name:
# filename: os_info.py
import platform
print(platform.system())
When executed, this script will print out the name of your operating system. To run it, save the code to a file named "os\_info.py" and execute it using your preferred Python interpreter. You can also copy and paste the code directly into your interpreter's REPL (Read-Evaluate-Print Loop) if supported.
--------------------------------------------------------------------------------
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: Can you run such script and test that it works.
user_proxy (to assistant):
Can you run such script and test that it works.
--------------------------------------------------------------------------------
assistant (to user_proxy):
I'm an AI text-based assistant, so I don't have the ability to execute or run scripts or code myself. My role is to help you generate, understand, and troubleshoot Python and Shell scripts. If you write a Python script (like the one provided in the previous response), you can test it on your local machine by saving the script into a file (with a .py extension) and then running that file using a Python interpreter like IDLE, PyCharm, or Jupyter Notebook. The result will be printed out in the console or terminal window for you to see.
You can also try out interactive Python sessions using your preferred Python interpreter (REPL) by copying and pasting the code directly into it and executing it there.
To ensure that the script works correctly, make sure you have a working Python installation on your system before running any Python scripts or code examples I provide in the future.
--------------------------------------------------------------------------------
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation:
>>>>>>>> NO HUMAN INPUT RECEIVED.
>>>>>>>> USING AUTO REPLY...
user_proxy (to assistant):
--------------------------------------------------------------------------------
assistant (to user_proxy):
If you encounter issues during execution, feel free to share them with me so we can work through any errors together.
I'd be glad to help you explore and learn more about programming using Python if you have any questions or need assistance!
--------------------------------------------------------------------------------
Provide feedback to assistant. Press enter to skip and use auto-reply, or type 'exit' to end the conversation: exit
By default pyautogen cannot execute code on your environment. You can configure it code. Remember that running LLM generated code can be risky. As a best practice, always review the code before running it. To avoid to interact with your computer it could run in a docker container.
Second example
In the second example I’ll show you how to use the same LLM with 2 different roles without human intervention. See the code of the example in the file example2.py
This is what I got after a couple of tries:
import os
import subprocess
Click to expand!
def get_file_md5(filename):
try:
md5 = subprocess.check_output(['md5sum', '--quiet', filename]).decode().strip()
return md5
except Exception as e:
print(f"Error while computing MD5 for '{filename}' - Error Message: {e}")
return None
def get_file_size(filename):
try:
stats = os.stat(filename)
return stats.st_size
except Exception as e:
print(f"Error while getting file size for '{filename}' - Error Message: {e}")
return None
def get_packages():
packages = []
for package in os.listdir('/var/lib/dpkg/info'):
if not package.endswith('.list'):
continue
with open(os.path.join('/var/lib/dpkg/info', package), 'r') as f:
lines = f.readlines()
for line in lines[1:]:
fields = line.split(' ')
if len(fields) < 3 or not all(char.isalnum() or char == '_' or char == '-' for char in fields[0]):
continue
packages.append((fields[0], os.path.join('/var/lib/dpkg/info', package)))
f.close()
break
return packages
def compare(packages):
mismatches = []
for package, package_file in packages:
files = [file for file in os.listdir(os.path.dirname(package_file)) if not file.endswith('.md5') and (file.startswith('.') or '~' not in file)]
for file in files:
fullpath = os.path.join(os.path.dirname(package_file), file)
new_md5 = get_file_md5(fullpath)
current_size = get_file_size(os.path.join(package, file)) if os.path.exists(os.path.join(package, file)) else 0
if new_md5 is not None and new_md5 != get_file_md5(os.path.join(package, file)):
mismatches.append((package, file, new_md5, current_size))
elif current_size != (get_file_size(fullpath) if os.path.exists(fullpath) else 0):
mismatches.append((package, file, current_size, get_file_size(fullpath)))
return mismatches
def main():
all_packages = get_packages()
mismatches = compare(all_packages)
if len(mismatches) > 0:
print("Mismatches found:")
for package, file, md5, size in mismatches:
print(f"Package '{package}', File '{file}'")
if md5 is not None and size is not None:
print(f"Current Size: {size}, New Size: {md5}")
else:
print(f"Current Size: {size}, New Size: Unknown")
else:
print("No mismatches found.")
if __name__ == "__main__":
main()
Reference code is from here
That is not yet quite right but it is a starting point. What I see as difficult here is to then debug the code. You didn’t write it and still you do not yet understand it. To really making it working the code comprehension is a must…And here I see the limit of the used AI models.
What I noted is that the agent is remembering the previous conversation and is using it to generate the next one. This is a good feature that can be used to improve the conversation but I didn’t yet found a good way to control it.
Third example
The third and last example I am going to use 2 different LLMs to do the given task. In this case the Coder will use the latest model LLAMA3 from Meta while the user proxy will use the same LLM as before, the Mistral model. The code is in the file example3.py
In this example I am also logging the outout in a sqllite database. This is a good way to keep track of the conversation and to improve the agent.
As part of the code generation and test process the script can also try to invoke sudo commands. For security reason run it in a confined environment and surely where sudo is protected by a password or even better in a docker environment.
The result of the execution is:
import subprocess
import hashlib
import os
Click to expand!
def get_installed_packages():
return subprocess.check_output(['dpkg', '--list']).decode().splitlines()
def get_file_info(package_name, file_name):
output = subprocess.check_output(['apt-file', 'ls', package_name]).decode()
lines = [line.strip() for line in output.split('\n') if line]
file_info = None
for line in lines:
if file_name in line:
parts = line.split('/')
file_info = {'package': package_name, 'file': file_name,
'current_size': os.path.getsize(os.path.join('/var/lib/dpkg/', parts[-1])),
'modification_time': str(int(os.path.getmtime(os.path.join('/var/lib/dpkg/', parts[-1])))))
return file_info
def compare_md5sum(package_name, file_name):
md5sum = subprocess.check_output(['dpkg', '-s', package_name, file_name]).decode().split(':')[1].strip()
expected_size = int(md5sum)
actual_size = os.path.getsize(os.path.join('/var/lib/dpkg/', file_name))
return (expected_size != actual_size), expected_size, actual_size
def report_differences(package_name):
for package in get_installed_packages():
if 'package:' not in package:
continue
parts = package.split(': ')
package_name_parts = parts[1].split()
if len(package_name_parts) > 1 and package_name_parts[0] == package_name:
package_info = None
for file in ['README', 'LICENSE']:
file_info = get_file_info(package_name, file)
if file_info:
size_diff, expected_size, actual_size = compare_md5sum(package_name, file_info['file'])
if size_diff:
print(f"Package: {package_name}, File: {file_info['file']}, Current size: {actual_size}, New size: {expected_size}, Modification time: {file_info['modification_time']}")
if not size_diff:
print(f"No differences found for package: {package_name}")
def main():
if len(sys.argv) > 1:
report_differences(sys.argv[1])
else:
for package in get_installed_packages():
if 'package:' not in package:
continue
parts = package.split(': ')
package_name = parts[1].strip()
print(f"Checking package: {package_name}")
report_differences(package_name)
print()
if __name__ == "__main__":
main()
That looks good but it still broken. Reference code is from here
At then end of this example you can see something like this:
{
"Cost info": {
"usage_including_cached_inference": {
"total_cost": 0,
"mistral": {
"cost": 0,
"prompt_tokens": 1291,
"completion_tokens": 318,
"total_tokens": 1609
},
"llama3:8b": {
"cost": 0,
"prompt_tokens": 6045,
"completion_tokens": 2000,
"total_tokens": 8045
}
},
"usage_excluding_cached_inference": {
"total_cost": 0,
"mistral": {
"cost": 0,
"prompt_tokens": 1291,
"completion_tokens": 318,
"total_tokens": 1609
},
"llama3:8b": {
"cost": 0,
"prompt_tokens": 6045,
"completion_tokens": 2000,
"total_tokens": 8045
}
}
}
}
This is the cost of the execution. You can see that the Mistral model is used for 1609 tokens while the LLAMA3 model is used for 8045 tokens. This is a good way to keep track of the cost of the execution in case you are using a paid service like OpenAI.
Interesing feature
The agent remembers the previous conversation and uses it to generate the next one. It does it writing the data on an sqlite3 DB.
I found this in the example execution dir in the folder .cache:
.cache/
.cache/41
.cache/41/cache.db
.cache/41/d0
.cache/41/d0/09
.cache/41/d0/09/eae1c54bec01b87feec7ea1a2152.val
If you want to get rid of its memory remove the cache.db file or update the task.
Alternatives
- Devin - Is it fake? I do not think so but its capabilities still need to be really open evaluates.
- OpenDevin - It isn’t fake! This is an opensource alternative to Devin. It is still in a very early stage but it is promising. You’ll see soon a demo here.
Conclusion
Although the idea of having your own agents at home is very cool, the reality is that it is still very difficult to make it work. The AI models are still not able to generate code that is working out of the box. The generated code needs to be reviewed and tested before running it. This is a very time consuming task and it is not yet clear if the generated code is really helping to save time.
I still need to deep dive in pyautogen library to understand how to control the conversation and how to improve the generated code. Also while writing this post I found another interesting project that I will test soon: Autogen-studio
What does it mean?
Python Virtual Environment
A Virtual Environment is a tool to keep dependencies required by different projects in separate places, by creating virtual Python environments for them. It solves the “Project X depends on version 1.x but, Project Y needs 4.x” dilemma, and keeps your global site-packages directory clean and manageable.
SQLite
SQLite is a lightweight, file-based relational database management system. It is self-contained, serverless, and does not require any configuration or setup. SQLite is widely used in embedded systems, mobile applications, and small-scale database applications due to its simplicity and efficiency.


